这篇文章用来记录一些我在工作中踩过坑的真实案例。
1. count + join 明明用到了索引,为什么还是那么慢?
1 | select count(*) from tb_proj_cst t1,tb_cst t2 where t1.cst_id = t2.id and t1.proj_id='abc'; |
为什么要这么写?
这个count查询场景是应用在客户列表管理中的,列表取数是需要拿到客户真实信息(也就是cst表的数据),而由于历史原因t1表存在一定的脏数据,如果不过滤掉,分页就会出现问题。这个查询的实际执行过程是怎样的?
explain查看该语句执行计划对这两个表使用的join type
1 | Table Join Type |
ref 和 eq_ref 都是用到索引,区别是eq_ref用到的索引是唯一的(PRIMARY KEY 或 UNIQUE NOT NULL index)。
t1 的 cst_id 和 proj_id 都是有索引的。单看这一条语句,基本上很难再去挖掘什么优化空间。如果单执行这句
select count(*) from tb_proj_cst where proj_id='abc';
查询速度是非常快的,那应该就是join的问题。
首先,我们先了解一下join的执行过程。join查询用的是嵌套循环联接算法(如果被驱动表上没有用到索引的情况下会使用块嵌套循环联接算法,比较复杂,这里先不展开了,以及MySQL 8.0.20版本后已经不再使用,改用哈希联接Hash Join Optimization)
这个例子join使用的伪代码类似如下
1 | for each row in t1 matching reference key { |
这样算的话,实际的扫描行数就是约等于满足条件的 t1 row*2
通过追踪优化器方法,查看最终选择的执行计划和实际扫描行数是否符合猜测
1 | { |
优化器选择了tb_proj_cst作为驱动表(t1)(因为用上了proj_id索引的条件,它相对于tb_cst就变成了“小表”),
查询返回结果:14351,扫描行数:28703,符合猜想
- 引申思考,为什么直接count的扫描行数约为join count的一半,但是查询时间却快了远不止2倍?
猜想:count会选择最小辅助索引树来扫描,因为辅助索引树的叶子节点只带pk信息,聚集索引树的叶子节点是带上整个row data的,而无论单独count报备表还是单独count客户表,都是直接扫描辅助索引树,但是带上了join就必然会用到主键索引
- 实际是怎么解决的?
把脏数据干掉了好像
2. 如果联表查询中多表都有同一个字段,且都有索引,where时选择哪一个呢?
以下4个SQL的业务意义都是一样的,表示查出某个项目下有成交佣金的交易数量(简化了一下,实际上还有很多其他条件,所以才会用到联表)。
涉及两个表: 佣金表tb_brokerage和交易表tb_trade
这两个表上都有项目IDproj_id这个字段,且都建了索引。
分别执行,查看每个SQL的扫描行数。
- SQL1 佣金表为驱动表。使用
佣金表的proj_id查询
1 | SELECT VARIABLE_VALUE INTO @a FROM INFORMATION_SCHEMA.session_status WHERE variable_name = 'Innodb_rows_read'; |
结果:1378
- SQL2 佣金表为驱动表。使用
交易表的proj_id查询
1 | SELECT COUNT(DISTINCT trade_id) FROM `tb_brokerage` b |
结果:18606
- SQL3:交易表为驱动表,使用
佣金表的proj_id查询
1 | SELECT COUNT(DISTINCT trade_id) FROM `tb_trade` t |
结果:7846
- SQL4:交易表为驱动表,使用
交易表的proj_id查询
1 | SELECT COUNT(DISTINCT trade_id) FROM `tb_trade` t |
结果:1386
这4个SQL查询的结果都是一样的,但实际性能差异却差很多。最差情况是SQL2,SQL1和SQL4的结果比较相近。
通过问题1的联表案例,我们基本可以达成共识的一个结论就是:联表查询时优化器会选择小表为驱动表。
因为这两个表都有proj_id的索引,所以理论上无论where条件里用的是哪个表的 proj_id,这张表都应该自然而然成为“小表”(ref),即使它的真是数据量并不是小的。那么可能发生的情况要么是SQL1,要么是SQL4,应该都不会太差。
出问题的真实SQL其实是这样的:
1 | SELECT |
当我在测试环境重现这个SQL的时候,试了n次都是SQL1的效果,用上了索引(唯一区别的in条件下join type是range),但当时这个慢SQL明明走的全表扫描。最后我把这个proj_id的条件不断扩大,当range的范围达到一定量时,优化器放弃了tb_trade的proj_id索引。这也有个前提是,交易表本身真实数量上是真正的“小表”。
这个问题也很好解决,不管业务数据大表小表,既然都要这个字段的索引,那就充分利用。
3. InnoDB的一个重要特性就是多版本并发控制(MVCC),这是为了保证并发安全。真是业务里有没有遇到过“不安全”的并发呢?
是有的。但其实不是MySQL的锅……
复现下这个场景,原渠道客户状态是基于cst_status,check_status这两个字段组合的。比如说
| cst_status | check_status | 状态 |
|---|---|---|
| 4 | 7 | 认购 |
| 4 | 8 | 签约 |
| 5 | 1 | 结佣 |
所有业务里这两个字段一定都是同时更新的,(代码里绝对不存在单独更新其中某一个的地方)
1 | update tb_cst_proj set cst_status=?,check_status=?; |
然而,有段时间,线上时不时就突然出现一条5-8的客户数据(这个状态是不存在的)。这个问题非常偶现,我们也从来没有重现过,所以每次出现都是修数据。
我们的代码里肯定没有写5-8的地方,但是客户不会信的。
我也非常困惑,反复看了好几遍相关代码。写状态的地方都是在事务里执行的,而且是两个一起更新,且只会按预定的几种状态组合值更新,怎么会出现这种完全凭空捏造的状态。
最后在某一次线上重现的机会下终于找运维要了binlog,定位时间查到,SQL执行的先后顺序大致如下:
1 | 1. 5-1 |
原来一开始方向就错了,竟然可以单独更新某个?这个其实是代码的问题,不展开了,贴在这大家了解一下就好。框架代码里的特殊逻辑:如果你写的update语句中的某个字段和旧的值比较没有变化,在拼接SQL语句的时候就不会加上这个字段。
整个过程完整理解下来就是这样:
| session1 | session2 |
|---|---|
begin; |
- |
select cst_status,check_status from tb_cst_proj where...; // 状态4-7 |
begin; // 事务2与事务1并发 |
| … (省略,和session2过程类似) | select cst_status,check_status from tb_cst_proj where...; // 第一次读,4-7 |
update rpc set 5-1; // |
x-lock |
commit; |
准备执行 update rpc set 4-8; |
| - | select cst_status,check_status from tb_cst_proj where...; // 第二次读,4-7 |
| - | … (比较update的字段,cst_status还是4,没变,过滤掉 |
| - | update tb_cst_proj set 8; |
| - | commit; |
session1模拟的是业绩通知的结佣场景,session2模拟的是交易通知的场景。业绩功能刚上线的时候,用了这两个队列去分别处理这业绩和渠道交易的业务,并发场景非常普遍。后来做了一系列优化改进,不赘述了。
试想一下,如果InnoDB的隔离级别是提交读,是不是可以避免这种情况呢?
其实可以(我认为),但是没必要。首先,这个问题是代码逻辑引发的,可重复读本身没有问题,且对更多场景下更安全。其次,这个业务(初版)的设计是否完全合理,也应该考虑下。
4. 按时间排序,翻页怎么取到了重复数据?
分别执行以下两个SQL,模拟按修改时间排序和翻页的场景,执行结果如图。(为了先排除null值的影响,加上过滤条件modify_on is not null)
1 | # 第一页 |
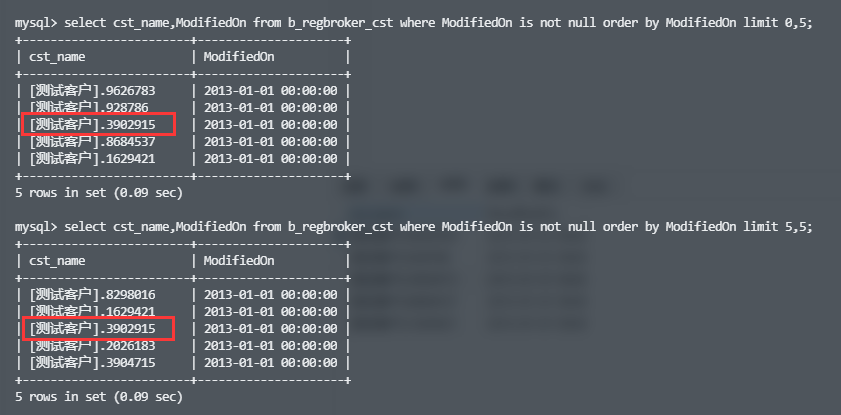
结果发现有一个结果重复出现了两次。
官方文档对这个的解释比较简单:
If multiple rows have identical values in the ORDER BY columns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns.
原因是在MySQL 5.6的版本上,优化器在遇到order by limit语句的时候,做了一个优化,即使用了优先队列(priority queue),priority queue使用的是堆排序的排序算法,,而堆排序是一个不稳定的排序方法,也就是相同的值可能排序出来的结果和读出来的数据顺序不一致。
什么情况下会用到priority queue?
在排序字段上没有索引,且排序量不大的情况下(也就是通常使用limit的情况下),优化器就会选择使用优先队列。
如何避免?
(1) 尽量避免在非索引字段上进行排序,如果业务上需要要大量频繁使用此字段排序,最好还是加索引。
(2) 如果只是偶尔用到该字段排序,可以在order by上加上主键,保证每次读取顺序都是一致的。
如果索引字段上存在NULL值会发生什么?
1 | # 正序 |
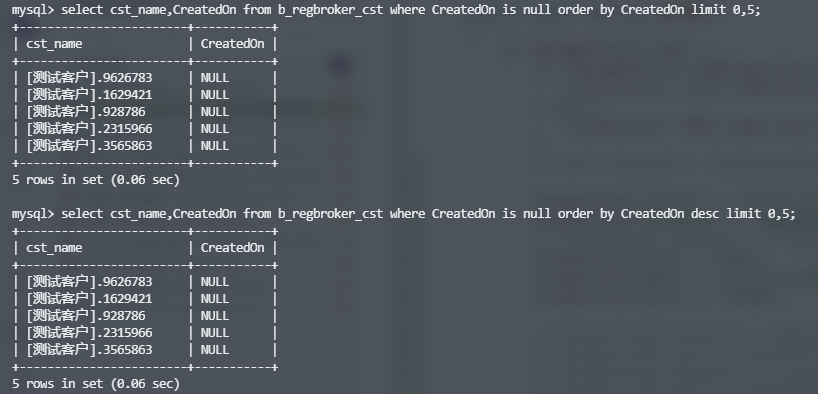
null值是不参与排序的,正序倒序取出来都是一样,所以这种情况下分页的业务也可能存在问题。我们尽量在定义字段的时候就使用not null,或给定默认值。对于已经存在的业务,避免这种情况也可以使用order by [null索引,主键]的方法。
5. 业务里有没有可能引发死锁的逻辑?
答案是有的。
简单描述一下这个业务场景,业务规则下有++竞争模式++和++保护模式++,
前提
(1) 如果是竞争模式,这个客户会保存到竞争分组表中。接下来即使有保护模式客户写入,那么他们就会形成一组竞争客户(反之不会)。
(2) 任何竞争模式中的客户,都会在无效时被移除。
(3) 当自己无效后,会去查竞争表中是否还有和自己同一分组下的竞争数据,如果刚好只剩一条,而这条客户还是保护模式,就要把这一条也移除。
竞争分组表主要字段如下
1 | id |
模拟以下这种场景:
| session 1 (张三无效) | session 2 (李四无效) | session 3 (王五无效) |
|---|---|---|
begin; |
- | - |
delete from competition where id=1; |
- | - |
select id from competition where group_id='abc'; //结果有两条,不处理 |
- | - |
commit; |
begin; |
begin; |
| - | delete from competition where id=2; row 2 x-lock |
delete from competition where id=3; row 3 x-lock |
| - | select id from competition where group_id='abc' |
select id from competition where group_id='abc' |
| - | 只剩id=3 且是保护带看 准备执行 delete from competition where id=3; |
只剩id=2 且是保护带看 delete from competition where id=2; |
| - | 等待 row3 lock… | 等待 row2 lock… |
InnoDB 是使用 wait-for(等待图)的方式来进行死锁检测。用到两个链表:(1) 锁等待信息链表 (2) 事务等待链表
这个场景下事务信息链表是 t2-t3
锁等待信息是row2 t2:x - t3:xrow3 t3:x - t2:x
这个图就是这样,存在回路就说明存在死锁
1 | graph LR |
这个问题是怎么解决的?
目前其实还没解决……报错较少,暂时还没有造成过大影响(发生死锁,InnoDB会选择回滚undo量最小的事务,在程序里就是异常失败,重新入列,最终还是被无效掉,表面上看业务还是“无损”的)
但如果解决的话,我的思路是把select放在delete前,如果除了自己只剩一条其他的保护带看,就同时删掉,这样一次性申请写锁,不会两边互相等待。
6. 数据升级,int类型转varchar遭遇的深坑
业务场景是这样的,表A与表B的对应关系是一对多,原本是通过A表的主键(自增)ID关联的,由于自增ID经常遭遇数据迁移的种种问题,于是A表新增了一个长度36的uuid字段,B表的关联ID也全部更新为该字段。
理论上,正常的升级流程就是:
(1) A表新增字段,并生成唯一的uuid
1 | ALTER TABLE `tbl_a` ADD COLUMN `uuid` varchar(36) NOT NULL DEFAULT ''; |
(2) 更新B表字段类型为varchar
1 | ALTER TABLE `tbl_b` MODIFY COLUMN a_id VARCHAR(36) COMMENT 'A表uuid'; |
(3) 通过原关联关系(自增id关联)批量更新为uuid关联
1 | UPDATE `tbl_a` a, `tbl_b` b SET b.a_id = a.uuid WHERE b.a_id = a.id; |
正常情况下,如果你自己按此方法测试,是不会轻易踩到坑上的。这是因为第三步只执行了一次,如果你的脚本被重复执行,就是巨大灾难。
造成这个问题的原因就是MySQL的隐式类型转换
简单来说,上面的步骤三里的更新条件是b.a_id=a.id,而这两个字段类型已经不一样,MySQL中字符串类型字段与int类型的字段之间比较会将字符串强制转换为int,假设A表id=1的数据uuid是’3abcd…’,那么模拟重现就是:
第一次:目前B表的a_id都还是数字,会直接找出a_id='1'的数据,更新为a的uuid ‘3abcd…’
第二次:B表的这条数据在第二次比较时被强制转换为int,’3abcd…’就变成了3,这次执行就会把这条数据更新为A表的自增ID为3的那条数据的uuid了
如此一来,数据就全乱套了。而且uuid通常的生成规则都是按时间戳等,前缀基本是一样的,可能这一批都是3开头,那么所有数据经过二次执行后都变成一样的关联id了,这就是大灾难啊。
慢SQL排查的一些建议
追踪优化器
- 基本用法
1 | # Turn tracing on (it's off by default): |
- 输出
1 | { |
这个json树非常长,很难阅读,你可以快速搜索 "chosen": true 查找优化器对每种优化方案的选择。或者只查看最终的refine_plan
查看系统变量信息
1 | FLUSH STATUS; |
相关字段:
Handler_read_key基于键读取行的请求数。如果此值很高,则表明您的表已为查询正确索引。Handler_read_next按键顺序读取下一行的请求数。如果要查询具有范围约束的索引列或进行索引扫描,则此值将增加。Handler_read_rnd_next读取数据文件下一行的请求数。如果要进行大量表扫描,则此值较高。通常,这表明您的表未正确建立索引,或者未编写查询以利用您拥有的索引。
扫描行数
1 | SELECT VARIABLE_VALUE INTO @a FROM INFORMATION_SCHEMA.session_status WHERE variable_name = 'Innodb_rows_read'; |
==备注:==
- 在线上数据库别这么查,因为每分每秒都有很多事务在进行,不是只有你这一条数据,得到的这个值是不准的,没什么参考性。
- 你可以在你自己的干净环境下查看不同语句的返回行数来优化语句
- 如果你的MySQL版本是5.7以上,就不要查
INFORMATION_SCHEMA.session_status了,改用performance_schema.session_status(在MySQL 8.0SHOW语句全部基于基础的Performance Schema表)
选择索引的建议
查看Cardinality值
1 | show index from table; |
实际上cardinality是一个预估值,而不是一个准确值。在实际应用中,cardinality/n_rows_in_table 应尽可能地接近1。如果特别小,就要考虑是否有必要创建这个索引。